Extending PySEF¶
Deriving new DR methods¶
The SEF allows for easily deriving novel DR techniques by simply defining the target similarity matrix. For the current implementation this can be done by defining a function that adheres to the following signature:
def custom_similarity_function(target_data, target_labels, sigma, idx, target_params):
Gt = np.zeros((len(idx), len(idx)))
Gt_mask = np.zeros((len(idx), len(idx)))
# Calculate the similarity target here
return np.float32(Gt), np.float32(Gt_mask)
The target_data, target_labels, sigma, and target_params are passed to the .fit() function. During the training this function is called with a different set of indices idx and it is expected to return the target similarity matrix for the data that correspond to the indices defined by idx.
For example, let’s define a function that sets a target similarity of 0.8 for the samples that belong to the same class, and 0.1 for the samples that belong to different classes:
def sim_target_supervised(target_data, target_labels, sigma, idx, target_params):
cur_labels = target_labels[idx]
N = cur_labels.shape[0]
N_labels = len(np.unique(cur_labels))
Gt, mask = np.zeros((N, N)), np.zeros((N, N))
for i in range(N):
for j in range(N):
if cur_labels[i] == cur_labels[j]:
Gt[i, j] = 0.8
mask[i, j] = 1
else:
Gt[i, j] = 0.1
mask[i, j] = 0.8 / (N_labels - 1)
return np.float32(Gt), np.float32(mask)
Note that we also appropriately set the weighting mask to account for the imbalance between the intra-class and inter-class samples. It is important to remember to work only with the current batch (using the idx) and not use the whole training set (that is always passed to target_data/target_labels). You can find more target function examples in sef_dr/targets.py.
The target that we just defined tries to place the samples of the same class close together (but not to collapse them into the same point), as well as to repel samples of different classes (but still maintain as small similarity between them). Of course this problem is ill-posed in the 2-D space (when more than 3 points per class are used), but let’s see what happens!
Let’s overfit the projection:
proj = KernelSEF(train_data, train_data.shape[0], 2, sigma=1, learning_rate=0.0001, regularizer_weight=0)
proj.fit(train_data, target_labels=train_labels, target=sim_target_supervised, iters=500, verbose=True)
train_data = proj.transform(train_data)
and visualize the results:
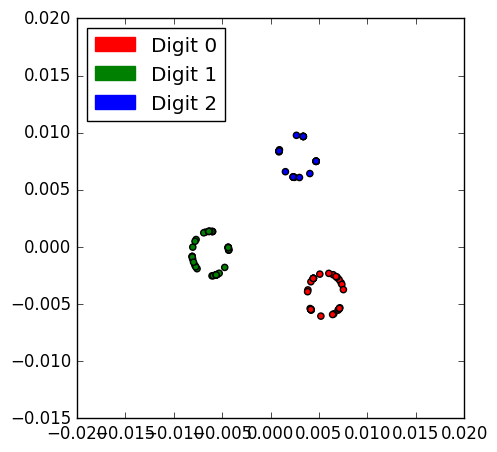
Close enough! The samples of the same class have been arranged in circles, while the circles of different classes are almost equidistant to each other!